This is a reposting with some updates of a post from a couple of years ago. It is a huge decision to make at the beginning of a project as to which language to use and why. As the founder of Slideshare said when asked if he regretted not using Java instead of Ruby his response was that the question was mute, that he wouldn’t even be there talking if he had use Java. Sure Java would have scaled better and Ruby had concurrency issues but Slideshare would not have succeeded, at least not as fast, or possibly not even existed had they used Java.
Related is a discussion of functional programming verses object oriented programming
- http://blog.fogus.me/2013/07/22/fp-vs-oo-from-the-trenches/
- https://news.ycombinator.com/item?id=6083770
Update Aug 2013
Fascinating article about how languages are becoming more expressive
http://redmonk.com/dberkholz/2013/07/23/are-we-getting-better-at-designing-programming-languages/
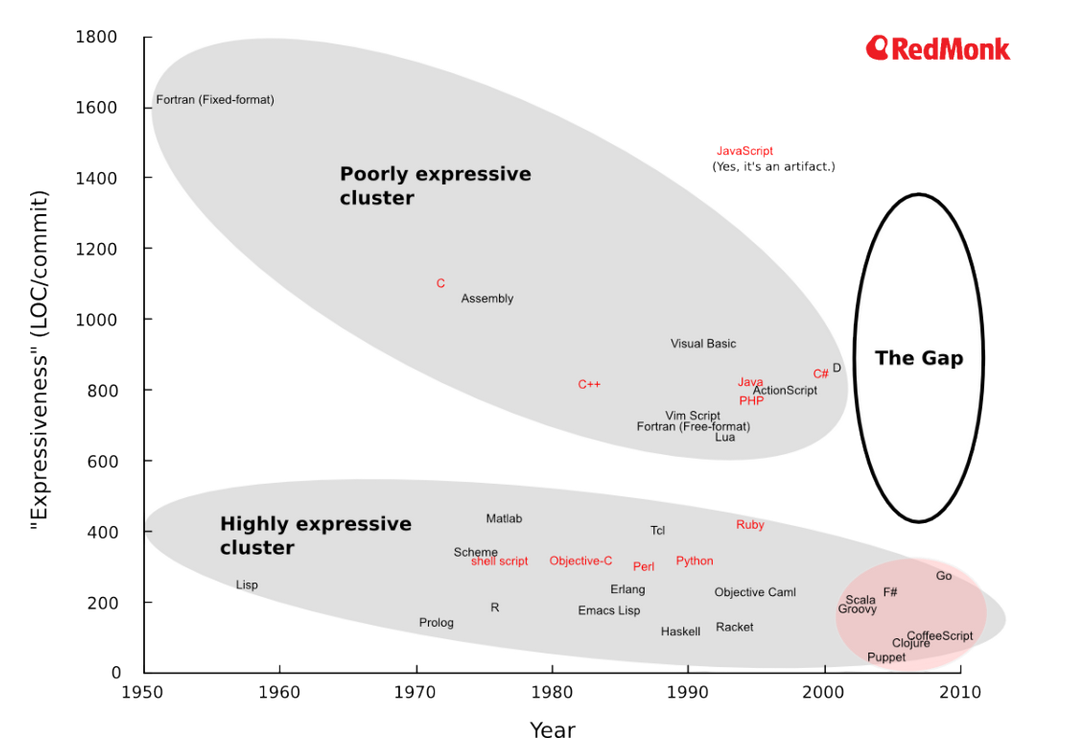
http://redmonk.com/sogrady/2013/07/25/language-rankings-6-13/
Update July 2013:
Larry Wall: “Java is sort of the Cobol of the 21st century” , http://www.youtube.com/watch?v=LR8fQiskYII
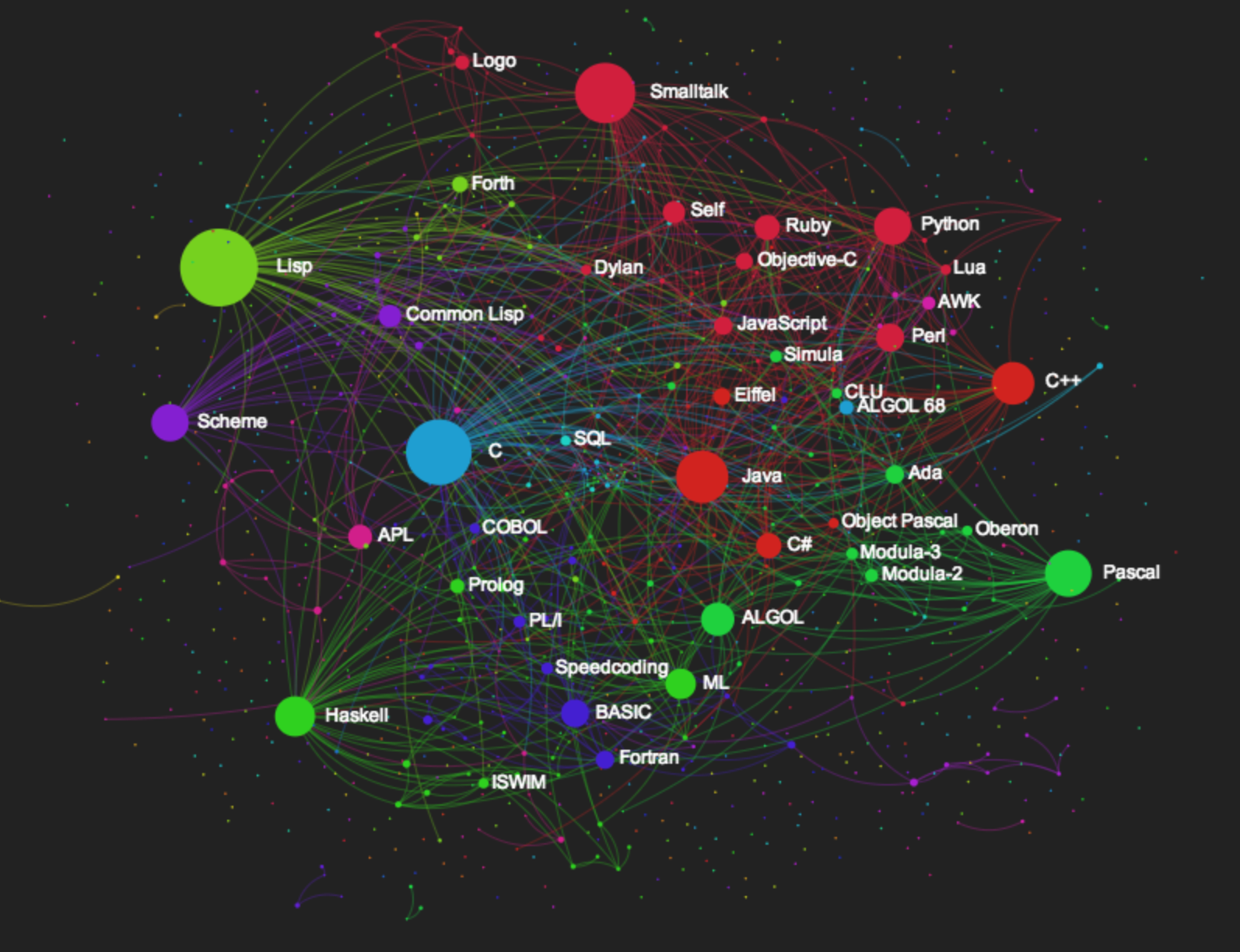
Another perspective on languages , the most influential languages:
Update June 2013: Python rockets to ascension and Java becomes lack luster
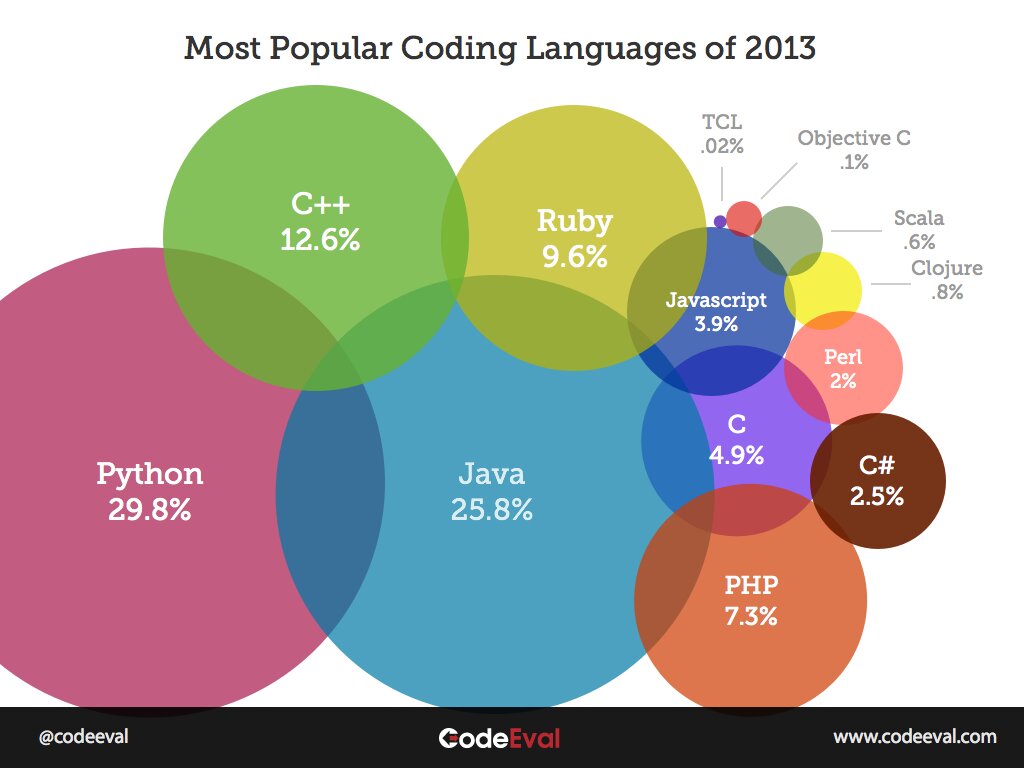
http://blog.codeeval.com/codeevalblog/most-popular-programming-languages-of-2013
What to choose
A more popular car will have better servicing as parts and skills will be common. A fast car is compelling but sometimes speed is easily sacrificed for comfort.
Recently the question of language efficiency verses productivity has been nagging me. The nagging question includes what languages, frameworks and packages are best for collecting data, analyzing data and exposing the data in a rich UI via a web browser.
Productivity
Here is an interesting graphic on speed of the programs in various languages

http://hinchcliffe.org/img/weblanguagecomparison2.png
Now the above graphic might be hard to read (wish it was larger) but what it is indicating is that Python is roughly 10x times slower in execution time to than the equivalent programs in Java. On the other hand the expected productivity gain for a programmer is 5-10x faster in Python than Java. Now on the surface my reaction is “OK, it’s faster to program in Python, ok, but Java is 10x faster so it’s clearly the choice!”, but if I put the numbers into real life I’m like OMG – imagine a Python program that takes 1 day to write, now that same program would take 5-10 days in Java!? Thats a huge deal. Hands down, I’m going to program in Python (or something other than Java). I can deal with some runtime performance issues.
Should a company program in Java or Python? What if Python would take a year to bring to market? What if the Java verison took 5-10 years ?! When asked whether if he could go back and recreate Slideshare in some other language than Ruby,Jonathan Boutelle, said the question is mute. If they had written it Java instead of Ruby they wouldn’t even be having the conversation. Sure Ruby had some scaling issues for them, but they released Slideshare on the market and became successful.
Here is another graphic on productivity from the book “From Java to Ruby”

The data is base on a study of productivity in C, Java, Perl, Python: http://page.mi.fu-berlin.de/prechelt/Biblio//jccpprt_computer2000.pdf
As far as productivity comparisons, I think the following two images of Python vs Java explain it nicely:
Python

Java equivalent
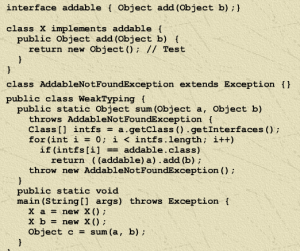
http://blog.chenzhongke.com/2010/05/why-python-is-more-productive-than-java.html
For a down and out dirty view of Java sprawl that further exacerbates productivity check out:
http://chaosinmotion.com/blog/?p=622
(as a rebuttal try pursing hello world in gnu packaging : http://ftp.gnu.org/gnu/hello/hello-2.6.tar.gz )
Performance
Here is a fascinating site with empirical data on speed of languages


http://shootout.alioth.debian.org/
Current speed might be a bit misleading as popularity will impact the efforts put into the issues of a language and a language that is popular though maybe less efficient will see improvements, for example it’s interesting to see the improvements in Java over the years, and now to see the improvements in Ruby. Though Ruby is slower than Scala and Scala’s productivity may even be better than Ruby, Scala doesn’t, yet, have the market momentum, thus the assurances that it is a language to invest in now.
Also if speed of the language is an issue the solution is not to throw the baby out with the bathwater, ie throw out the productive programming language altogether and go for a fast one such as C or JAVA but to find the areas of slowness in the productive framework and replace those with a fast function in another language, ie polyglot programming.
Popularity
another interesting image on the current usage of languages:

http://www.dataists.com/2010/12/ranking-the-popularity-of-programming-langauges/
Languages mentioned in job postings as % and % increase


http://www.soa-at-work.com/2010/02/it-job-trends-which-technologies-you.html
The issues of showing total growth verses % growth lend itself well to heat map representation. Here is a heat map from O’Reilly:

(Interesting to all the Oracle folks: PL/SQL shows a 51% growth 2007-2008.
Here is data from O’Reilly on growth over time, showing Python and C# growing steadily:

http://radar.oreilly.com/2009/02/state-of-the-computer-book-mar-22.html
http://radar.oreilly.com/2011/02/2010-book-market-4.html
Tiobe Index

http://www.tiobe.com/index.php/content/paperinfo/tpci/index.html
Here is google trends normalized by C programming (with out normalization all trends are down because google trends show hits normalized by all traffic and as general traffic increases verses computer geek searches general computer geek searches trend downwards)

Interesting how Ruby seems to be trending down (as normalized against C searches)
another perspective: Google Insights:
| Google Insights for Search |
|
|
|
 |
Gadgets powered by Google |
Just for Fun
here is how I started my morning, a fun video on Python, that catalyzed the above discussion: http://blip.tv/play/g4VigqrwEgI%2Em4v
other links
- humor relief to this blog post:A cheeky st0ry of programming languages http://james-iry.blogspot.com/2009/05/brief-incomplete-and-mostly-wrong.html
- popular programming languages: http://www.readwriteweb.com/hack/2012/06/5-ways-to-tell-which-programming-lanugages-are-most-popular.php
- hello world in different JVM/CLR languages http://carlosqt.blogspot.com/2010/06/most-active-net-and-jvm-languages.html
Kyle Hailey Uncategorized











 Seeing more and more questions on “where do I start with Oracle if I want to be a DBA?” My perspective is a bit off since I’ve been surrounded by Oracle for over 20 years. I hardly remember what it was like to start with Oracle and starting with Oracle now in 2013 is quite different than starting with Oracle in 1990.
Seeing more and more questions on “where do I start with Oracle if I want to be a DBA?” My perspective is a bit off since I’ve been surrounded by Oracle for over 20 years. I hardly remember what it was like to start with Oracle and starting with Oracle now in 2013 is quite different than starting with Oracle in 1990.






recent comments